Appendix A2
From 'neural net' simulations of rival views
Introduction
In some of the essays in this volume I have illustrated how infants are capable of circular re-enactment of a model's movements in face-to-face situations, entailing a virtual mirror reversal of the model's movements as perceived. Differing from egocentric observation (such as in autism), such perceptual mirror reversal would have to be supported by some sort of altercentric system, perhaps even neurons sensitized to altercentric perception, operative in the brain, perhaps in competition with systems or networks that subserve egocentric perception. In the last part of this appendix I make some preliminary notes on a project in progress to explore by connectionist simulation networks "trained" to realize such mirror reversal, compared to networks 'trained' only for egocentric perception.
Proceeding from the assumption that competitive networks are involved, I shall first succinctly report from some neurocompational explorations with competitive Neocognitron networks (Fukushima 1986) which we 'trained' from rival perspectives and exposed to ambiguous visual stimuli (Bråten & Espelid 1989).
Perception of Visual Ambiguity: Neurocomputational Explorations
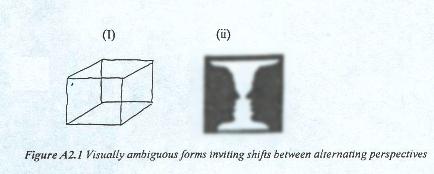
Faced with figures inviting visual ambiguity such as (I) Necker's cube or (ii) Rubin's vase (Fig. A2.1), humans, when setting their mind to it, are able to shift between rival images evoked by the same form, for example alternating between seeing a vase and seeing two faces, or between seeing the cube facing left or facing right.
Neurocomputational approaches to visual ambiguity
Visual ambiguity in the form of the cube presented by L. A. Necker (Fig. A2.1 (I)) in 1832 has been subject to much discussion and many attempts in terms of connectionist modelling and neurocomputation in terms of parallel distributed processing (PDP). For example, Rummelhart et al. (1986) report from runs of a simulation of Necker cube processing by a connectionist network model in terms of the two rival views of the cube front facing left or the cube front facing right. They show that the system will (almost always) end up in a situation in which all the units in one subnetwork are fully activated and none of the units in the other subnet are activated. That is, the system settles in the stable state (or fixed point) of interpreting the Necker cube as either facing left or facing right. This occurs when the input values are low relative to the strength of the constraints among units. Under high input condition, the implemented system occasionally yield the "impossible" interpretation that the cube has two front faces. While this has the merit of retaining both the left and the right hand perspective in operation, it makes for an "impossible perception" through fusing the two.
In terms of his neural net model, Malsburg proposes that a coherent image comes about through temporal coherence of the firing of neurons, exhibiting synchrony in spite of their locations in distant columns. When there are two superposed figures, then cell assemblies coding for the different figures should be expected to be activated in alteration (Marlsburg et al. 1978, 1986).
Neurocomputational nets facing visual ambiguity without contextual clues
Fukushima (1986; 1988) has developed "self-organizational" multi-layered network model, Neocognitron, which allows for recognition of superimposed figures, such as Figure A2.2 (I). Having backward paths it is capable of selective feature 'attention'. Neocognitron can "recognize" different handwritten versions of characters and digits, and can also handle certain types of visual ambiguity. For example, when trained to recognize the individual patterns in this set (0, 1, 2, 3, 4) Neocognitron will 'attend' and recognize selectively three distinct patterns in this order (4, 2, 1) in the below stimulus (Fig.A1.2 (I)).

When faced, however, with the kind of ambiguous stimuli illustrated in Fig. A2.1, or in Fig. A2.2 (ii), calling upon rival perspectives, we found that such a single multilayer network of the Neocognitron kind could not cope.2 T /-æ E C /-æ T
This is Selfridge's example of instant disambiguation by virtue of available context.
For example, the above label (Fig. A2.2 (ii)) may be read as 125, as IZS, as 12 S, as IZ 5, as I 25, etc. When a single Neocognitron network version 'trained' to recognize both digits and characters, was exposed to the above series, the implemented network failed to come out with significant results, at least in our trials.
The idea of competitive networks
When, however, one such network was trained to "recognize" digital forms, and another was trained to "recognize" letter forms, each came out with clear forms according to their respective "perspectives". Our basic idea is this. Define a perspective P as a related set of viewpoints, p1,p2,...,pn, which evoke companion viewpoints, q1,q2,...,qn, as members of a complementary set Q. Let these complementary preferences in viewing the world be imposed by the systems designer or "trainer". Train competing networks each to operate from a single perspective, for example from a perspective P that restrains the world to faces, while the other is 'trained' from the rival perspective, Q, limiting its viewpoints only to vases or goblets. When exposed to visual ambiguity, without contextual clues, permit these P- and Q-nets to operate concurrently, each from their own (trained) perspective. Then, when faced with Rubin's vase, the P-net is expected to recognize the silhouetted faces, while the Q-net is expected to see the vase. When allowed to engage in 'dialogue' with their respective outputs at a higher-order level, they will complement each other, one of them will prevail, given other clues that comes from other sources, perturbing or supporting the viewpoints in question.
When one of the networks, the P-net was trained to "recognize" digital forms, was exposed to the pattern (ii) in Figure A2.2, it generated forms conforming to the digits (1 2 5), while the Q-net, trained to "recognize" letter forms, generated forms conforming to the letters (I Z S). Thus, each came out with clear forms according to their respective "perspectives" when exposed to the partly deformed patterns of Fig. A2.2 (ii), and even to highly distorted forms conforming to the respective perspective. Thus, while a single network appears to defy "training to recognize" patterns of similar form that conform to elements of both the above series,3 the trained P- and Q-nets appeared capable of "recognizing" even highly distorted forms as conforming to viewpoints in terms of their respective perspectives.4
The fact that human perceivers -- when devoid of contextual clues -- can alternate between two such complementary viewpoints suggests that humans are able to house complementary viewpoints in parallel or near-parallel. The kind of perceptual alternating invited by Rubin's vase (Fig. A2.1), for example, appears to presuppose a structure capable of embodying complementary perspectives in concurrent or near-concurrent operation.
Altercentric (mirror) reversal in face-to-face learning situations
Structural prerequisites for the kind of perceptual alternation explored above may relate to a structural prerequisite for the kind of perceptual mirror reversal invited by the gestures and movements of a facing other. In the project now turned to I proceed from the assumption that competitive systems or networks subserving, respectively, egocentric and altercentric perception somehow must be at play.
Again, as in the above use of neurocomputational simulations to study the behaviours of implemented networks 'trained' to process in terms of rival viewpoints, we study the behaviour of networks 'trained', respectively, to reproduce a copy of a given input pattern and to generate the reverse of that pattern. Nothing much is expected to come out of such crude connectionist simulations providing, as it were, mostly an explorative playground. Yet, it is worth while pursuing for this reason: the very process of implementing and studying the behaviours of such competitive networks compels one to consider possible operational prerequisites for such processes in real life.
When asked to do what the facing model is doing
As has been documented in this volume and elsewhere (chapter 5 in Bråten (ed.) 1998: 105-124), infant learners appear able to feel to be moving with the other's movements, entailing a virtual mirror reversal of the facing other's movements as perceived. This I have termed 'altercentric participation', the very reverse of egocentric perception. For example, when an adult model raises her hands with palms outwards and asks a child facing her to do what she does, the ordinary child will imitate that gesture correctly with palms outwards (Figure A2.3 (left)). A child confined only to egocentric perception, however, will fail to execute such a mirror reversal. Identifying the inside of his own hands with the inside of the model's hands shown to him, such a child is expected to raise arms with palms inwards (Figure A2.3 (right)). This has been predicted to apply to autism from the assumption that the ordinary capacity for such mirror reversal has been impaired or blocked in children with autism, creating problems in face-to-face situations (Bråten 1994).
The illustration to the left in figure A2.3 pictures what normal children do when invited to do what the adult is doing, entailing mirror reversal, while someone with egocentric perspective, such as in autism, are expected to have problems: Seeing the resemblance between the inside of the model's hands with the insides of his own, and being incapable of a virtual reversal of the model's movements as felt, the child with autism who understands the request to do as the adult does, has been predicted to do what is being seen from own position, and will raise hands with inside inwards. This has been confirmed (cf. inter alia Whiten & Brown in Bråten (ed.) 1998:260-280).

On the neurosociological prediction and speculations about possible architecture
My neurosociological prediction (1997) that an altercentric (mirror) system would be found in humans (essay no 16, this volume), followed from the postulate of virtual other mechanism. Pondering upon the possible architecture by which the infant's bodily self and virtual other could complement each other, I realized that their relation would have to be chiral (Greek for handedness) like the way in which the left hand and the right hand only can become identical in form if one of them is reflected by a mirror.
The radical step, however, to the expectation that perhaps even neurons sensitized to altercentric perception might be found, was voiced upon reflecting on what I had learnt at a King's College workshop on perception of subjects and objects. Here John O'Keefe (1992) raised the issue of the relation between self-consciousness and allocentric maps, that is maps of the landscape in front of you, represented in a such manner that you represent it independent of your gaze direction in relation to the landscape, transcending a view from an egocentric perspective. O'Keefe and Nadel (1978) suggest that the hippocampus implements a cognitive map and performs spatial computation. Rats are able to find their way in an environment even when novel trajectories are necessary, they hold, in virtue of hippocampal maps that holds information about allocentric space, as contrasted to egocentric space. In a study of a monkey moved to different places in a spatial environment, O'Keefe (1984) found evidence of place cells, dependent upon the place where the monkey was, and different from view cells, defined primarily by the view of the environment, and not by the place where the monkey was. Feigenbaum and Rolls (1991) had investigated whether the spatial views encoded by primate hippocampal neurons use egocentric or some form of allocentric coordinates (see Rolls 1995).
This inspired me, then, to venture the prediction that neurons sensitized to altercentric (mirror) reversal would be found in infant learners who re-enact a facing model's novel movements or gestures. When considered realized at the neurophysiological level, it would entail that there be neural cells responding to the gestural movements of others not just egocentrically (that is view-dependent), not just allocentrically (that is independent of your own position and perspective), but altercentrically, that is from the other's position or perspective. If such neural cells should not be found, then infant learners' altercentric participating in the facing model's movements would have to be subserved by some higher-order system for mirror reversal.
Thus, in addition to networks operating upon egocentric and allocentric cells in the learner's system, alterocentric cells or a higher order mirror systems is expected to exist and be activated in order that the learner be able to do what the facing others does, i.e. to re-enact from the learner's position what the learner has felt to be co-enacting with the model in virtue of alteroceptive reversal of the model's movements.
May such an altercentric (mirror) system be operative already in neonatal imitation?
One may speculate about whether or not such a mirror system is dependent upon being sensitized or "trained" in order to be operative. I expect that it is. While predicting it to be innate, I am reluctant to attribute such a mirror system already in operation in neonatal imitation in the first hour of life. But this is a matter for further investigation. Heimann (1997, personal communication) suspect it to be at play already from the outset. There is, indeed, the possibility is that is already present at birth, while not observed in children who later are diagnosed as autistic (cf. Heimann's analyses in Bråten (ed.) 1989:89-104).
When some neonates in Meltzoff & Moore's (1989) study exhibit reversed head rotation when imitating the facing model after a pause, this might indicate neonatal capacity for mirror reversal. And yet, even if there may be such capacity already at birth, I would expect it to be dependent upon interactional nurture in order to be sustained and strengthened. While capable of including actual others in their companion space in felt immediacy, young infants would depend, I suspect, on such face-to-face nurture in felt immediacy in order that such a mirror reversal system be sensitized and "trained" to respond to companions in an altercentric manner. The first months -- before infants engage with their companions in joint attention towards objects in the surround -- may turn out to be critical in that respect.
In 1973 Malsburg presents a nerve net model for the visual cortex of higher vertebrates. His point of departure are the findings of Hubel and Wiesel 1962, 1963). They found neurones selectively sensitive to the presentation of light bars and edges of a certain orientation to be organized in functional columns according to orientation, and such that neighbour columns on the cortical surface tend to respond to stimuli of similar orientation. Malsburg, then, models the orientation sensitive cells in terms of these two mechanisms: development of pattern sensitive cortical cells by a self-organizing process involving synaptic "learning", and the ordering of functional columns as a consequence of intracortical connections. A certain proportion of the model cells is orientation sensitive already before the learning principle is applied. When subjected to "training" to only a restricted set of stimuli during the training period, the model entails that the cortical neurones will specialize to these stimuli and become insensitive to other stimuli. This is consistent with what Wiesel (1987) reports about how newborn monkeys and kittens exhibit marked changes in the ocular dominance column when influenced by visual training.
This, then, when applied to human infants, would lead one to expect that altercentric neuronal firing, complementing the egocentric neurons of the bodily self, would be dependent upon critical nurture during the first months in order to complement the kind of allocentric neurons stimulated and trained when infants join with companions in paying attention to objects in the common surroundings.
There is, however, another possibility. Instead of attributing the capacity for alteroceptive reversal to rest upon and be dependent upon specific altercentric nerve cells, whether or not dependent upon training, the capacity for alteroceptive reversal may rest upon a more globally organized capacity which operates upon egocentric and allocentric, place-dependent and view-dependent neural responses, and carry out such translation and alteroceptive reversal in a supramodal manner. Hence, a more global mirror system for altercentric participation may be envisaged
On connectionist simulation of some elements
The above are the kind of questions in the background for the crude connectionist explorations in progress, albeit without any expectations of illuminating reply. My limited objective is just to demonstrate the operational feasibility of 'training' different versions of implemented 'neural net' simulators to reproduce input patterns, corresponding to the Gestalt of a manual gesture, in a copying (egocentric) manner and in a reversed (altercentric) manner.
We first begun by way of connectionist simulation such different responses to the arm raising Gestalt pictured in figure A2.3. Although we did manage to train for reversal, it turned out to be too cumbersome to explore by our fairly simple networks, incapable as they were to respond to movements; we had to translate into a sequence of pattern snapshots representing the move from lowered to raised hands.
While I hope to renew our efforts with more refined network models with reference to arm raising, I found in the meantime a simpler pattern which could be explored without interposing representations of movements. This is the modern hand sign for 'Jesus', represented by a gesture marking a stigma in the hand, illustrated to the left of Figure A2.4. At the top to the left is shown the hand sign as seen by a perceiver facing the enactor of the sign. Below is shown the reversed image corresponding to how the perceiver upon re-enactment of the gesture will see the sign from his own (egocentric) stance. For the facing perceiver, then, in order to re-enact the gesture as seen made by the other, the image has to be reversed. This inversion pattern has turned out to be easy to explore even by a simple three-layer recurrent network (of the family shown in Figure A2.4(ii), but without contextual nodes), compared with recognition of from an egocentric stance.
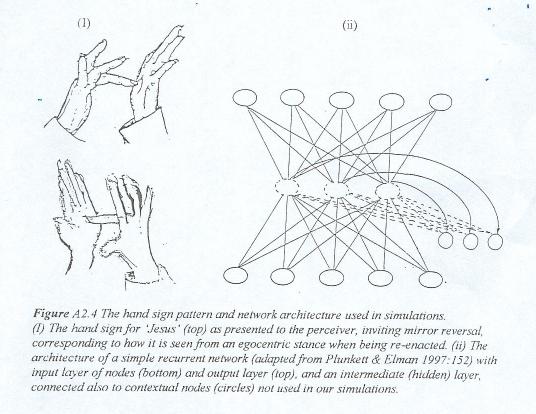
The three layer architecture of simple recurrent networks (Elman 1990; Plunkett & Elman 1997) has been used as a first candidate in these explorations of the hand sign. It has been designed for connectionist simulation of perceptual detection of patterns displaced in time. Such an implemented network consists of one input layer (symbolized at the bottom in Figure A2.4 (ii)), one output layer (symbolized at the top), and an intermediate layer with 'hidden nodes'.5
For example, in some of our attempts, using a low-resolution image of the hand sign, we have used two identical three-layer networks, and Ego-net and an Alter-net, each with an input layer of 838 nodes and an output layer of 838 nodes, and with 50 nodes in the intermediate (hidden) layer. While the Ego-net is trained to reproduce an image of the input pattern without any reversal, the Alter-net is trained to reproduce the reverse image (corresponding to the pattern at the bottom of Figure A2.4 (I)). Although it should have been expected, given the design of tlearn programme, I was surprised to see that given the same number of training sweeps6 (400 presentations of the input pattern), the Ego-net and the Alter-net did not differ much in terms of error or time. It made me realize that if there be distinct systems, subserving respectively egocentric and altercentric perception in humans, then upon being sensitized or trained, they may not differ much in terms of expediency and delay time. If, on the other hand, the altercentric system depends on egocentric input for its subsequent mirror reversal, then differences in delay time should be expected.
In another experimental run, the Ego-net was compared to an Alter-net that alternatively was trained to respond both in terms of an ego-input and in a reversed manner. Given the same number of training sweeps, the Ego-net learnt to reproduce its target more speedily and accurately than the Alter-net. Again, this is to be expected.
Preliminary conclusion
The above leads me to suspect that an evolved systems sensitized to altercentric (mirror) perception may be as speedy in operation as a system operating from an egocentric perspective, incapable of reversal. At least this is what our crude and preliminary exploration with simple recurrent networks trained from these rival perspectives. While due to the architecture of the tlearn networks used, for that simple architecture it did not much matter whether the target pattern was reversed or not. For a network, however, that has to cope both with an egocentric target and an altercentric target it certainly makes a difference.
Thus, explorations even with a crude and simple network architecture may have put us on the track of illuminating this question: does mirror reversal depend on altercentric neurons being discharged, or rather on a system at a higher operative level that also has to cope with egocentric input? If the latter is the case, then time difference should be expected.
For those who would object to the kind of reductionism they see to be entailed by the above prediction, speculations, and crude connectionist simulations, I would like to point out by way of conclusion: They concern questions about how the very self-other connecting link between face-to-face participants may be subserved by, not reduced to, neuropsychologcial mechanisms. Bearing in mind the dynamic interpersonal companion systems level examined in many of the essays in this volume, I expect tenable replies to entail a transition from neuropsychology to neurosociology.
.
1 This appendix includes notes for a talk November 19, 1996, at the weekly seminar in my Theory Forum group 1966-67 at The Centre for Advanced Study, Oslo, The first part refer to a project on visual ambiguity, carried out with Rune Espelid at Bergen Scientific Centre IBM (Bråten & Espelid 1989), in which Fredrik Manne and Petter Møller assisted with implementation in C. The second part contains preliminary notes for a project in progress, with Anders Nøklestad as my research assistant, to explore by crude connectionist simulations competing networks trained to process input patterns as presented and by mirror reversal. For the hand-raising pattern (fig. A2.3)) programmes have been implemented in Java 1.02, while for the 'Jesus figure' (fig. A2.4) the tlearn programme (from the Oxford site, UK) is being used.
2 The question is relevant for the kind of visual ambiguity exhibited by technical document patterns for which the immediate neighbouring context provides no clues for correct interpretation by conventional automated means Normally, we use the context to disambiguate, for example when the same distinct pattern, such as this /-æ, in one instant may be seen as "H" and in the next instant may be seen as "A":
3 Two different adapted versions of the Neocognitron model have been implemented in C and run on IBM 3090/200VF and on an IBM 6150(RT/PC). Trained to recognize nine clearly distinguishable patterns conforming to the elements in this series, (0,1,2,..9), they are capable of recognizing partly deformed input patterns in the Gestalt of the respective numbers, and even to extract superposed forms. However, when confronted with ambiguous stimulus that may permit recognition both as characters and numbers, we were unable -- even when a variety of inhibition values were tried out -- to train a particular network to recognize characters and numbers in such a manner,, that it could recognize a character pattern and a number pattern in the same distorted stimulus.
4 So-called back-propagation, i.e. regulatory feedback correcting pattern based on some externally set criteria or target pattern, works within the limited perspective that each net has been "trained" for, but not across the networks, separately implemented and trained from different perspectives, implying different targets. Conversation in view of global or more distant contextual information from the past may be required for resolving their difference, for example, in the case of exposure to the series in Fig. A1.2 (ii), about how labels in this document tend to adhere to the rule (character, character, digit). Should later a different solution be required, there may be reversal to the discarded alternatives by virtue of the parallel competitive net.
5 In addition, special context nodes (symbolized by circles) may serve to store a copy of the hidden node activation pattern at t, feeding it to the hidden nodes at t+1. The hidden nodes activation patterns at t would thereby be afforded to the hidden nodes at t+1 in conjunction with the new input pattern at t+1.
6 During network training, error is assigned to the hidden units by back propagating the error from the output, where the error reflects. the deviance of the output pattern from the training target pattern. The error on the output and hidden units is used to change the weights on the intermediate and input layer. Simple recurrent network learning and backpropagation through time, of the kind implemented in tlearn, has been developed by Plunkett, Elman and others to explore processes in children's language acquisition, for example, learning the English past tense.